Demonstrations
Model is trained on simple demonstrations as shown.
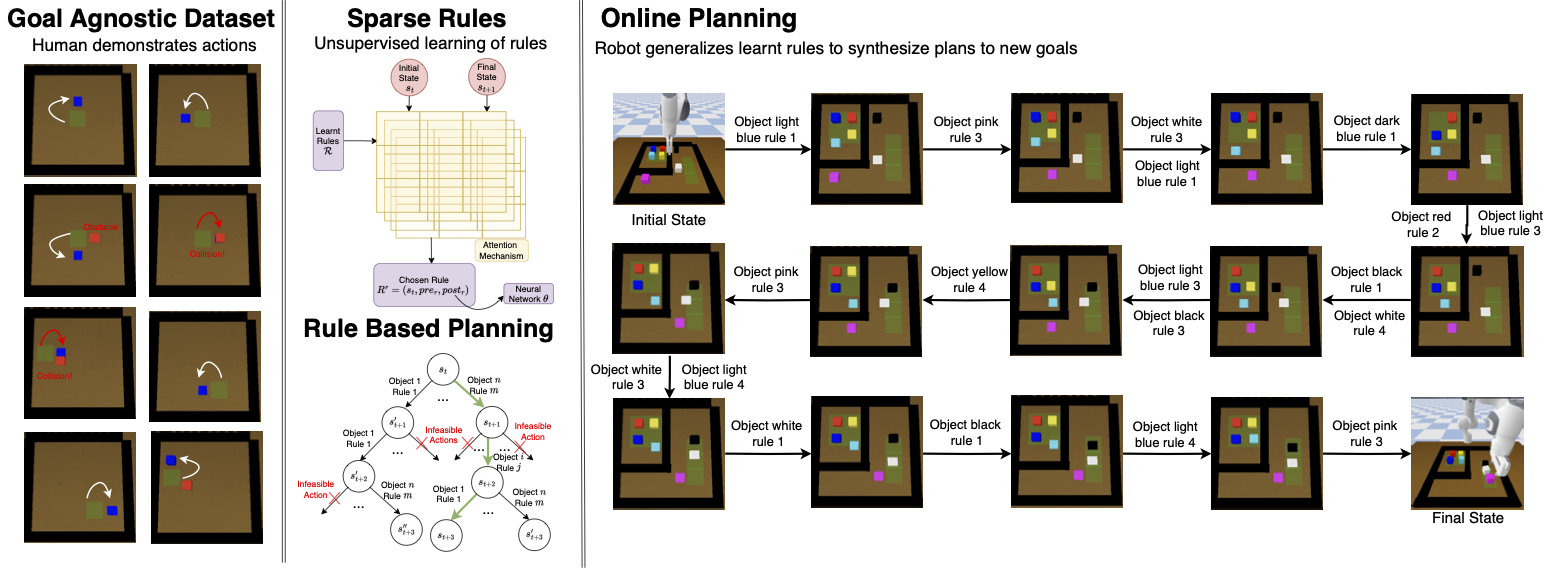
As robots tackle complex object arrangement tasks, it becomes imperative for them to be able to generalize to complex worlds and scale with number of objects. This work postulates that extracting action primitives, such as push operations, their pre-conditions and effects would enable strong generalization to unseen worlds. Hence, we factorize policy learning as inference of such generic rules, which act as strong priors for predicting actions given the world state. Learnt rules act as propositional knowledge and enable robots to reach goals in a zero-shot method by applying the rules independently and incrementally. However, obtaining hand-engineered rules, such as PDDL descriptions is hard, especially for unseen worlds.
This work aims to learn generic, sparse, and context-aware rules that govern action primitives in robotic worlds through human demonstrations in simple domains. We demonstrate that our approach, namely RLAP, is able to extract rules without explicit supervision of rule labels and generate goal-reaching plans in complex Sokoban styled domains that scale with number of objects. RLAP furnishes significantly higher goal reaching rate and shorter planning times compared to the state-of-the-art techniques.
Model is trained on simple demonstrations as shown.
Model is then tested on much more complex planning tasks in more complex world instances. We can see from the below example that the generalizable potential of our technique is very high. We are able to achieve this by learning rules from demonstrations (RLAP) and then planning with these learnt rules (RB-MCTS). Both these techniques are described in deeper depth in the paper.
@inproceedings{RLAP2024,
title = {Unsupervised Learning of Neuro-symbolic Rules for Generalizable Context-aware Planning in Object Arrangement Tasks},
author = {Sharma, Siddhant and Tuli, Shreshth and Paul, Rohan},
booktitle = {IEEE International Conference on Robotics and Automation},
year = {2024}
}